最近在工作中用到了MinHash[1],使用它做了一些文檔去重和查找相似數據的任務。工欲善其事,必先利其器。要想用好一個算法/工具,就需要深入瞭解它的底層細節。本文簡單記錄了我對MinHash方法的理解,並展示了一些簡單的實驗。
本文先介紹了將文檔視爲數字的集合這一思想,並演示了幾種不同的實現方案;既然文章可以視爲數的集合,那麽自然可以用集合的交并比這一度量來衡量文章之間的相似度;接著,文章介紹了MinHash的核心:對集合的最小值進行采樣,借此估測集合間的交並比;最後,文章介紹了MinHash作爲一種局部敏感哈希(Locality Sensitive Hashing,LSH)具有怎樣的特點,可以如何利用LSH的特點來加速文檔去重過程。
在文章的開頭,我們先羅列和導入後續會需要用到的包:
import numpy as np
import pandas as pd
from typing import Tuple, List, Set, Dict
from collections import defaultdict
import random
import time
import matplotlib.pyplot as plt
random.seed(0)1 将文档看作集合
文檔可以看作是字符組成的序列。儘管現在使用RNN、Transformer等深度神經網絡來處理文本的方法已經十分普遍,但當要處理文本規模達到上百萬的量級時,忽略詞語的語義、語序,僅考慮其詞語構成,進行“機械的”相似度比較仍是一種有效的方法。
以文檔A"a rose is a rose is a rose"和文檔B"a rose is a flower which is a rose"為例,兩個文檔可以分別被拆解為如下的單詞:
A = ("a", "rose", "is", "a", "rose", "is", "a", "rose")
B = ("a", "rose", "is", "a", "flower", "which", "is", "a", "rose")將A和B分別表示為其使用到的單詞的集合是一種簡單的方法。除此之外,還可以考慮將相鄰的若干單詞組成“Shingle”(又被稱為n-gram),將文檔考慮為Shingle的集合。
顯然,Shingle可以被定義為字符串組成的n元組。
Shingle = Tuple[str]忽略Shingle的出現順序,我們可以將文章看作是Shingle的集合。我們分普通集合和多重集兩種情況分別討論。
下面的代碼展示了如何將一個文檔轉化為由Shingle構成的多重集。與普通的集合不同,多重集允許元素多次重複出現,這使得我們可以統計每種Shingle的出現次數。
代碼使用Dict來模擬多重集。函數返回的Dict統計了文檔中出現的每種Shingle的數量。
def doc_to_shingle_bag(doc: List[str], w:int) -> Dict[Shingle, int]:
assert w > 0, w
ret = defaultdict(int)
for i in range(len(doc) - w + 1):
ret[tuple(doc[i:i+w])] += 1
return ret
下面的代碼展示了將文檔A轉化為Shingle的多重集的結果。Shingle的大小分別被設置為1、2、4.
print(doc_to_shingle_bag(A, 1))
print(doc_to_shingle_bag(A, 2))
print(doc_to_shingle_bag(A, 4))defaultdict(<class 'int'>, {('a',): 3, ('rose',): 3, ('is',): 2})
defaultdict(<class 'int'>, {('a', 'rose'): 3, ('rose', 'is'): 2, ('is', 'a'): 2})
defaultdict(<class 'int'>, {('a', 'rose', 'is', 'a'): 2, ('rose', 'is', 'a', 'rose'): 2, ('is', 'a', 'rose', 'is'): 1})其實不考慮Shingle的出現次數,將文檔視為Shingle的普通集合也是可行的。這樣的做法稍微粗糙一些,但效率更高。
doc_to_shingles函數提供了將文檔轉化為Shingle的集合的方法:
def doc_to_shingles(doc: List[str], w: int) -> Set[Shingle]:
assert w > 0, w
ret = set()
for i in range(len(doc) - w + 1):
ret.add(tuple(doc[i:i+w]))
return ret print(doc_to_shingles(A, 1))
print(doc_to_shingles(A, 2))
print(doc_to_shingles(A, 4)){('a',), ('rose',), ('is',)}
{('rose', 'is'), ('is', 'a'), ('a', 'rose')}
{('is', 'a', 'rose', 'is'), ('a', 'rose', 'is', 'a'), ('rose', 'is', 'a', 'rose')}MinHash方法[1]提出使用交並比(又被稱為Jaccard相似度)來衡量文檔間的相似度(resemblance)。交並比(即交集大小與並集大小之比)的計算公式如下:
\[ J(A, B) = \frac{|A\cap B|} {|A\cup B|} \]
如果文檔被表示為多重集的話,我們可以使用下面的函數來計算其相似度:
def naive_resemblance_a(
shingles_a: defaultdict[Shingle, int],
shingles_b: defaultdict[Shingle, int]
) -> float:
i = 0
u = 0
for k in set(shingles_a.keys()) | set(shingles_b.keys()):
i += min(shingles_a[k], shingles_b[k])
u += max(shingles_a[k], shingles_b[k])
return i / max(u, 1e-6)下面的代碼對相似度計算結果進行檢查,可以看到計算結果與論文[1]提供的數據保持一致。
eps = 1e-6
ret = naive_resemblance_a(doc_to_shingle_bag(A, 1), doc_to_shingle_bag(B, 1))
assert abs(ret - 0.7) < eps, ret
ret = naive_resemblance_a(doc_to_shingle_bag(A, 2), doc_to_shingle_bag(B, 2))
assert abs(ret - 0.5) < eps, ret
ret = naive_resemblance_a(doc_to_shingle_bag(A, 3), doc_to_shingle_bag(B, 3))
assert abs(ret - 0.3) < eps, ret
print('All test cases passed.')All test cases passed.類似的,如下代碼提供了將文檔表示為Shingle的普通集合時,resemblance的計算方法,並作了檢查:
def naive_resemblance_b(
shingles_a: Set[Shingle],
shingles_b: Set[Shingle]
) -> float:
intersection = shingles_a & shingles_b
union = shingles_a | shingles_b
return len(intersection) / max(len(union), 1e-6)eps = 1e-6
ret = naive_resemblance_b(doc_to_shingles(A, 1), doc_to_shingles(B, 1))
assert abs(ret - 0.6) < eps, ret
ret = naive_resemblance_b(doc_to_shingles(A, 2), doc_to_shingles(B, 2))
assert abs(ret - 0.5) < eps, ret
ret = naive_resemblance_b(doc_to_shingles(A, 3), doc_to_shingles(B, 3))
assert abs(ret - 0.42857142) < eps, ret
print('All test cases passed')All test cases passed將Shingle的大小記為\(w\),從以上的計算中我們可以看到\(w\)越大,resemblance就对差異越敏感。
至此,文章展示了如何將文檔轉化為Shingle的集合,並用交並比衡量文檔相似性。在實際程序中,我們可以為每一種可能的Shingle分配一個id。至此,我們介紹了如何將文檔表示為數字的集合。
上文介紹的方法與MinHash論文[1]保持一致。但這種方法仍是粗淺的。在實際的應用中,我們可以考慮是否去除stop words(即“a”, “the”,“of”等對文章語義貢獻較小的詞彙)。我們還可以考慮合併單詞的不同形態,例如為“learn”、“learning”、“learned”賦予相同的id……除此之外,如何實現中文的分詞也是一個值得深入的問題。本文就不再就此作更多探討了。接下來,讓我們假設文檔已經被轉化為數字的集合。
2 用最小值估計文檔相似度
前文我們介紹了如何將文檔表示為數字的集合,我們將這種操作記為\(S(A, w)\),其中\(A\)為輸入的文檔,\(w\)為shingle的尺寸。
在後面的文章中,我們可以生成一些隨機集合用於實驗(跳過shingle操作)。假設變量vocab_size規定了集合的最大尺寸,下面的代碼能隨機為我們生成一些“文章”:
vocab_size = 60000
def random_doc(k):
return set(random.sample(range(vocab_size), k))random_doc(4){25247, 49673, 55340, 58343}如前所述,文章的相似度可以用交並比(又名Jaccard similarity)衡量。既然文章被表示為集合,那麼相似度的計算可以被實現為:
def Jaccard_similarity(doc_a, doc_b):
doc_a = set(doc_a)
doc_b = set(doc_b)
return len(doc_a & doc_b) / len(doc_a | doc_b)假設\(\Omega\)是所有可能的Shingle組成的集合。設\(\Omega\)是一個有序集,因此我們可以比較\(\Omega\)中所有元素的大小。對於\(\Omega\)的子集\(W\),定義 \[ \text{MIN}_s(W) = \left\{ \begin{aligned} &\text{W中最小的s個元素}, &\text{if} |W|\geq s \\ &W, &\text{otherwise} \end{aligned} \right., \] 定義 \[ M(A) = \text{MIN}_s(\pi(S(A, w))), \] 其中\(\pi:\Omega\rightarrow\Omega\)是定義在集合\(\Omega\)上的一個“置換”(即將\(\Omega\)集合作了一次“洗牌”,一一對應地將\(\Omega\)中的一個元素映射到另一個元素)。
那麼:
定理 1 \[ \frac{|\text{MIN}_s(M(A)\cup M(B))\cap M(A) \cap M(B)|}{|\text{MIN}_s(M(A)\cup M(B)|} \tag{1}\] 是文檔A和文檔B的resemblance的無偏估計(以置換操作\(\pi\)是隨機挑選的為前提)。
證明: 顯然 \[ \begin{aligned} \text{MIN}_s(M(A)\cup M(B)) &= \text{MIN}_s(\pi(S(A, w))\cup \pi(S(B, w))) \\ &= \text{MIN}_s (\pi(S(A, w)\cup S(B, w))) \end{aligned} \] 設\(\alpha\)是\(\pi(S(A, w)\cup S(B, w))\)中最小的元素,那麼 \[ \begin{aligned} P(\alpha \in M(A) \cap M(B)) &= P(\pi^{-1}(\alpha)\in S(A, w)\cap S(B, w)) \\ &= \frac{|S(A, w)\cap S(B, w)|}{|S(A, w)\cup S(B, w)|} \end{aligned} \] 假設\(\alpha\)是\(\pi(S(A, w)\cup S(B, w))\)中第二小、第三小……的元素,上式同樣成立。因此命題成立。
這實際上是一個關於“超幾何分佈”的期望的問題,你可以在網絡上查找相關討論。
以上介紹的命題就是MinHash工作的核心原理。接下來,文章使用代碼驗證這個命題,並演示相關函數是如何工作的。
首先,我們先實現\(\text{MIN}_s\)函數:
def min_s(doc, s):
doc = np.asarray(list(doc))
return -find_top_k(-doc, s) \
if len(doc) > s \
else docmin_s的實現使用到了find_top_k函數。我隱藏了它的實現,實際上find_top_k是一個返回數組中最大的\(k\)個數的函數,可以用排序法或者quick select算法實現。
假設我們有一個大小為\(4\)的集合作為輸入,那麼min_s取\(s=2\)時的輸出為:
d = random_doc(4)
print('document:', d)
print('min_s(document):', min_s(d, 2))document: {37120, 22297, 40130, 50311}
min_s(document): [37120 22297]MinHash中,隨機性的來源是對置換操作\(\pi\)的採樣。下面的代碼隨機初始化了一些候選的置換操作,可以作為\(\pi\)的候選。
random_permutations = []
for i in range(1000):
indices = list(range(vocab_size))
random.shuffle(indices)
random_permutations.append(indices)
random_permutation_index = 0def get_random_permutation():
global random_permutation_index
indices = random_permutations[random_permutation_index]
random_permutation_index += 1
random_permutation_index %= len(random_permutations)
pi = lambda x: [indices[i] for i in x]
return pi 接著實現\(M(A)\)函數。\(M(A) = \text{MIN}_s(\pi(S(A, w)))\),其代碼實現為:
def m(pi, doc, s):
return min_s(pi(doc), s)利用min_s和m函數,resemblance計算的實現就直觀明了了。根據公式 1,resemblance可以用如下代碼估計:
def estimate_resemblance(pi, doc_a, doc_b, s):
ma = set(m(pi, doc_a, s))
mb = set(m(pi, doc_b, s))
tmp = set(min_s(ma | mb, s))
return len(tmp & ma & mb) / len(tmp) 下面的程序檢驗了estimate_resemblance函數對resemblance的估計結果與真值(Jaccard similarity)的一致性。實驗表明MinHash所提出的方法確實能比較好地對Jaccard similarity進行估計。
errors = []
for i in range(8):
length_a = random.randint(10000, 30000)
length_b = random.randint(10000, 30000)
doc_a = random_doc(length_a)
doc_b = random_doc(length_b)
sim_j = Jaccard_similarity(doc_a, doc_b)
num_samples = 256
samples = []
for j in range(num_samples):
pi = get_random_permutation()
s = estimate_resemblance(pi, doc_a, doc_b, s=10)
samples.append(s)
resemblance_est = np.mean(samples)
# assert abs(sim_j - resemblance_est) < 1e-2
errors.append((sim_j - resemblance_est))
print('{}:{:.4f} ≈ {:.4f}'.format(i + 1, sim_j, resemblance_est))
print('Average error:', np.mean(np.abs(errors))) 1:0.2656 ≈ 0.2516
2:0.2224 ≈ 0.2391
3:0.1757 ≈ 0.1734
4:0.2111 ≈ 0.2066
5:0.2557 ≈ 0.2387
6:0.2848 ≈ 0.2785
7:0.1928 ≈ 0.1980
8:0.1944 ≈ 0.1961
Average error: 0.008473042802044726後續的方法[2]往往採用\(s=1\)的MinHash的特例。在\(s=1\)時,公式 1的含義就變為:
設\(A\)和\(B\)為待比較的輸入文檔,\(\pi\)為隨機採樣的置換。\(a=\min(\pi(A))\),\(b=\min(\pi(B))\),\(J(A, B) = P(a=b)\).
讀者可以自行通過實驗驗證:當\(s=1\)時,MinHash也能很好地估計文檔的相似度。
3 哈希函数
前文已經介紹了MinHash的核心思想,即基於隨機採樣的置換操作\(\pi\)選取最小的\(s\)個元素,根據這些元素是否相同,可以估計輸入文檔的相似度。但是隨機置換\(\pi\)的生成比較耗時。考慮到shingle集合一般可以通過哈希函數\(h(\cdot)\)轉化為範圍有限的數字,然後這些數字經過置換操作\(\pi:\Omega\rightarrow\Omega\)在變換為\(\Omega\)內的其它數字,我們可以假設哈希函數\(h\)內部已經實現了置換操作,從而將\(\pi\)省略掉。這種假設的前提是\(h\)的哈希碰撞很少。
以下代碼實現了一種哈希函數: \[ h_i(x) = (a_i x + b_i) \mod P \] ,其實現參考了chrisjmccormick的开源代码。
該哈希函數中,\(a_i\)和\(b_i\)分別是隨機採樣的係數,這使得哈希函數\(h_i\)具有隨機性,對應於原\(\pi\)的隨機性。
首先,我們需要隨機選取\(a_i\)和\(b_i\),在代碼中對應於coeff_a和coeff_b. 待要生成的哈希函數的數量記為num_hashes.
max_shingle_ID = 2**32-1
next_prime = 4294967311
num_hashes = 128
def pick_random_coeffs(k):
rand_list = []
for _ in range(k):
rand_index = random.randint(0, max_shingle_ID)
while rand_index in rand_list:
rand_index = random.randint(0, max_shingle_ID)
rand_list.append(rand_index)
return rand_list
coeff_a = pick_random_coeffs(num_hashes)
coeff_b = pick_random_coeffs(num_hashes)
print(coeff_a[:8], coeff_b[:8])[1725382162, 4099968420, 181011877, 2646584740, 2425745411, 1382556146, 2811366918, 584506969] [4024735497, 432468821, 4092063574, 1311785557, 3815225036, 3844735591, 2426666110, 66760331]那麼,記錄了num_hashes條隨機哈希函數的列表可以實現為:
from functools import partial
hash_functions = [
partial(
lambda x, i: (coeff_a[i] * x + coeff_b[i]) % next_prime,
i=i
)
for i in range(num_hashes)
]以下是一些例子,說明不同的哈希函數對於同樣的輸入,輸出是不同的:
hash_functions[0](0), hash_functions[1](0), hash_functions[0](0)(4024735497, 432468821, 4024735497)於是,對於輸入文檔doc,我們可以對應應用num_hashes條哈希函數,得到對應的哈希值作為它的“signature”。
def get_min_hash(doc):
hash_codes = [
min((hash_function(x) for x in doc))
for hash_function in hash_functions
]
return hash_codes 根據公式 1,signature的漢明距離(即數一數不同的哈希值的數量)就衡量了兩篇文檔的距離。讓我們用實驗來驗證這一點:
random_docs = [random_doc(random.randint(10000, 30000)) for _ in range(8)]
hash_codes = [get_min_hash(doc) for doc in random_docs]
errors = []
total_time_j = 0
total_time_min_hash = 0
for i in range(len(random_docs)):
doc_a = random_docs[i]
min_hash_a = hash_codes[i]
for j in range(i + 1, len(random_docs)):
doc_b = random_docs[j]
min_hash_b = hash_codes[j]
t = time.time()
sim_j = Jaccard_similarity(doc_a, doc_b)
total_time_j += time.time() - t
t = time.time()
resemblance_est = np.mean([a == b for a, b in zip(min_hash_a, min_hash_b)])
total_time_min_hash += time.time() - t
errors.append((sim_j - resemblance_est))
print('{}-{}:{:.4f} ≈ {:.4f}'.format(i, j, sim_j, resemblance_est))
print('Average error:', np.mean(np.abs(errors)))
print('Time Difference: {:.4}s:{:.4}s'.format(total_time_j, total_time_min_hash))0-1:0.1899 ≈ 0.2031
0-2:0.1655 ≈ 0.1406
0-3:0.2121 ≈ 0.2812
0-4:0.1410 ≈ 0.1562
0-5:0.1861 ≈ 0.1094
0-6:0.1992 ≈ 0.1562
0-7:0.1130 ≈ 0.1250
1-2:0.1965 ≈ 0.1719
1-3:0.2701 ≈ 0.2812
1-4:0.1685 ≈ 0.1250
1-5:0.2263 ≈ 0.2188
1-6:0.2462 ≈ 0.2109
1-7:0.1313 ≈ 0.1406
2-3:0.2153 ≈ 0.2422
2-4:0.1431 ≈ 0.1328
2-5:0.1900 ≈ 0.1719
2-6:0.2063 ≈ 0.2109
2-7:0.1174 ≈ 0.1484
3-4:0.1840 ≈ 0.1328
3-5:0.2553 ≈ 0.2031
3-6:0.2885 ≈ 0.2188
3-7:0.1425 ≈ 0.1484
4-5:0.1633 ≈ 0.1406
4-6:0.1732 ≈ 0.1484
4-7:0.1084 ≈ 0.1250
5-6:0.2399 ≈ 0.1875
5-7:0.1304 ≈ 0.1953
6-7:0.1370 ≈ 0.1484
Average error: 0.03030614381569787
Time Difference: 0.1847s:0.09761s我們注意到該方法確實能大體反應文檔間的Jaccard similarity。如果增大num_hashes,計算的結果可以變得更加準確。
此外,還可以看到比較signature的方法比直接計算Jaccard similarity要快上不少,這是因為signature的計算可以提前準備,而比較signature的漢明距離是很快的。
儘管將文檔轉化為Signature的方式加速了文檔的兩兩比較,但這種方法的時間複雜度還是\(O(n^2)\). 面對海量的大規模數據,有沒有能夠避免兩兩比對的,快速找出相似數據的方法呢?
4 局部敏感哈希
如前所述,我們希望避免大量數據將兩兩比對的情況。已知每個文檔都可以表示為一個由哈希值構成的列表,我們可以考慮两种简单的做法:
- 将所有哈希值完全一致的文档挑出来;
- 只要有一个任意位置,在列表的這個位置上哈希值重复,就将這些文檔視為重複;
首先注意到這兩種方法的時間複雜度都小於\(O(n^2)\),因為挑出哈希值重複的數據可以通過dict等數據結構實現;其次,这两种做法都是极端的。随着哈希函数数量的增加,1将挑不出任何数据,而2将返回所有数据——尽管如此,结合1和2,我们能得到一种折衷的,能实际应用的方案。
局部敏感哈希(Locality-Sensitive Hashing,LSH)就是這樣一種,實現1和2的折中的技術。LSH方法首先要求相似的文檔的哈希值有更大的概率相同,反之則希望它們大概率不同;其次,LSH方法將哈希函數分組,並鼓勵相似的文檔落入相同的bucket內。
接下來我們討論哈希函數的分組。一組哈希函數被稱為一個band。 设\(b\)为一个band内hash函数的数量,\(r\)為band的數量,於是使用到的哈希函數的總數為\(t=rb\). 那麼對於隨機選取的兩個文檔,它們的相似度為\(p\);那麼在使用MinHash的前提下,其哈希值相同的概率也為\(p\)。有如下等式成立: \[ \begin{aligned} \text{一个band内所有哈希值都相同的概率} &= p^r \\ \text{一个band内存在不同哈希值的概率} &= 1 - p^r\\ \text{所有band都不相同的概率为} &= (1 - p^r)^b \\ \text{至少存在一个完全相同的band的概率为} &= f(p) = 1 - (1 - p^r)^b \\ \end{aligned} \] 將這個函數繪製出來,我們可以看到這樣的圖像:
t = 128
rb_list = [
[32, 4],
[16, 8],
[8, 16],
[4, 32],
]
plt.figure()
for r, b in rb_list:
assert r * b == t
p = np.linspace(0, 1, 1000)
fp = 1 - (1 - p**r)**b
plt.plot(p, fp)
plt.legend(['r={};b={}'.format(r, b) for r, b in rb_list])
plt.xlabel('p')
plt.ylabel('f(p)')
plt.show()
plt.close()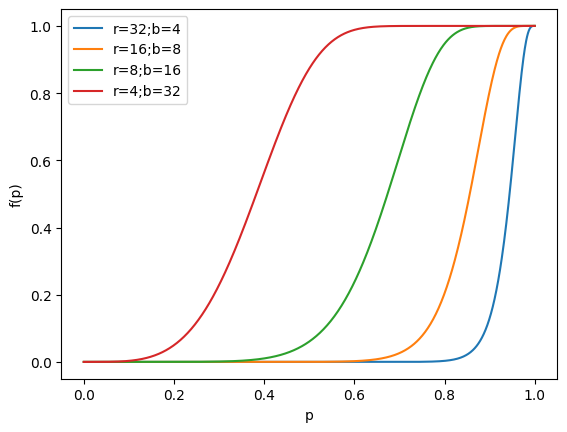
該函數的圖像是一個遞增的S形曲線。在\(p\)的值不超過某個閾值的時候,概率\(f(p)\)很小;反之一旦超過這個值,\(f(p)\)就驟然增大。
用通俗的話來說,MinHash方法具有一個很好的性質:相似的兩個文檔(\(p\)的值比較大)有很大的概率(\(f(p)\))使得至少存在一個band,這個band內的兩文檔的哈希值全部相同——這會使得它們落在同一個bucket內;函數圖像中中部的跳變意味著存在一個可以調控的界限,在這個界限兩端,文檔落在同一bucket內的概率有鮮明的差別。
對於實際應用,該函數圖像的“跳變點”是需要調控的一個重要參數。设我们希望提取相似度在阈值\(\tau\)以上的数据,那么上图的斜率最大点可以近似为\(\tau \approx (1/b)^{1/r}\),据此可以解出\(r,b\)的值。
5 總結
回想去年參與了一個大模型項目的數據管理,負責處理源數據,然後轉給資源部標註。在這個項目裡我沒有料到供應商給的源數據居然有大量的重複,就這樣把重複的數據發給資源部了……等到反應過來,已經不知道損失了多少錢。
_(¦3」∠)_
一開始用的是暴力的編輯距離或者TFIDF特征比較的方法去重,但隨著數據的增多,兩兩比較的暴力去重開始變得有點應付不過來。後來才學習了基於哈希的去重方法。基於哈希的方法能有更高的效率,精準度高,召回率不如暴力方法。但是深入了解了算法細節,結合項目數據的特征,還是能夠設計出好用的去重策略的。
6 一些參考資料
- MinHash Example
- MMDS text book
- http://www.mmds.org/